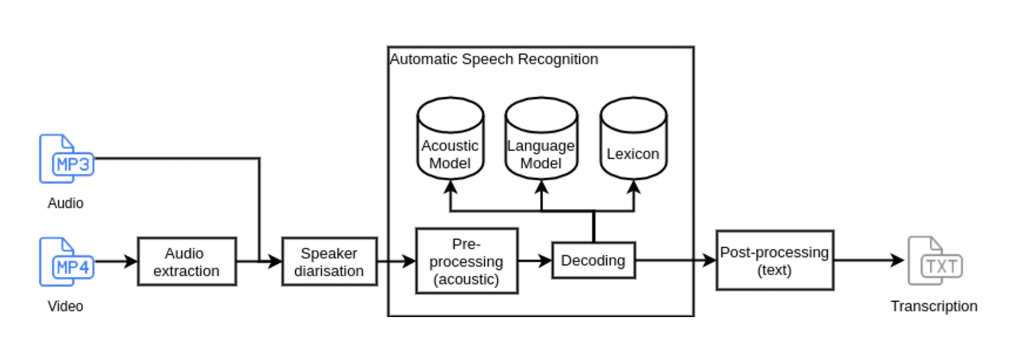
| YouTube, deuxième moteur de recherche après Google, est donc la plateforme principale sur laquelle votre contenu audio doit se trouver, pour peu que vous désiriez augmenter votre découvrabilité ou votre référencement. De nombreux outils de transcription existent aujourd’hui. Ces outils vous permettent de transcrire votre audio en texte et d’ajouter du sous-titrage automatique, voire de la traduction de ce sous-titrage. Mais ces outils demandent un gros travail manuel, ce qui réduit leur intérêt. Authôt fait partie des outils dont la fiabilité dépasse les 95% et tend vers les 100% après relecture humaine. Société française fondée en 2012 spécialisée dans la RAP, ou reconnaissance automatique de la parole, elle est aujourd’hui pionnière dans la transcription et le sous-titrage multilingue pour vos émissions et évènements. Voici pourquoi. La reconnaissance automatique de la parole – souvent improprement appelée reconnaissance vocale – est une technique qui permet d’analyser la voix humaine captée au moyen d’un microphone. La technologie transcrit ensuite, sous la forme d’un texte ou d’un fichier exploitable sur ordinateur. La RAP a pour but d’associer une séquence de mots à une séquence d’observations acoustiques. Elle comporte quatre modules. L’extraction de paramètres pour transformer le signal de la parole en séquences d’observation acoustique, le modèle acoustique qui permet de reconnaître une séquence de phonèmes grâce aux observations, un modèle linguistique qui reconnaît les mots probables grâce aux mots voisins et le dictionnaire phonétique qui décode le modèle acoustique et le modèle linguistique. “Cette technologie permet donc d’analyser la voix humaine dans une logique d’amélioration continue, grâce à l’intelligence artificielle et des technologies comme celles du deep learning”, indique Olivier Fraysse, cofondateur d’Authôt. “En à peine une vingtaine d’années, ces systèmes sont passés d’une reconnaissance d’un mot sur deux à la totalité d’un discours.” Les atouts pour les contenus audio Dans le monde de la radio et des podcasts, on travaille sur l’enregistrement, la captation audio et/ou vidéo, puis la diffusion de ce contenu pour qu’il soit le plus écouté, compris et partagé. Le référencement de ce contenu est un enjeu majeur et seul le texte aujourd’hui permet un bon référencement sur les moteurs de recherche ou sur YouTube. Le temps consacré au dérushage de l’audio en texte est un enjeu majeur, car il nécessite un travail manuel d’ajustement. Authôt vous permet de réduire ce temps par deux et propose également une vérification manuelle dans ses offres. Sous-titrage aux formats .srt ou .vtt, accessibilité de la transcription avec le HTML ou XML, indexation mais aussi traduction fiable des textes viennent s’ajouter aux contenus audio ou vidéo des stations de radio ou des podcasteurs simplement. Une technologie intelligente Le système RAP, ou ASR en anglais pour Automatic Speech Technology, ne fait pas tout. Il faut maîtriser les algorithmes et disposer de données qualitatives. “Notre équipe de recherche a le savoir-faire pour créer, modifier et améliorer un système RAP. Nous avons la capacité d’enrichir nos systèmes en lien avec le vocabulaire de nos clients grâce à des données extrêmement qualitatives qui proviennent de nos services humains de relecture”, confirme Olivier Fraysse. Les plateformes Authôt en ligne de transcription et de sous-titrage offrent des éditeurs avancés qui permettent aux utilisateurs de corriger facilement et rapidement le texte, puis de réaliser la synchronisation des sous-titres, voire de la traduire en direct. La société adapte même sa plateforme de transcription, traduction et sous-titrage en direct Authôt Live pour être compatible avec les formats de diffusion en direct RTMP ou HLS pour enrichir en temps réel les flux live… Authôt en quelques mots C’est en classe préparatoire de l’école d’ingénieurs ISEP que les deux fondateurs d’Authôt, Olivier Fraysse et Stéphane Rabant, se sont rencontrés. La société, créée en 2012, est la première application française en ligne de transcription automatique de la parole en texte. Avec 16 collaborateurs et plus de 39 000 utilisateurs en 2020, elle lance en 2021 Authôt University puis en 2022 Authôt Studio dédié au sous-titrage, tirant profit de leur savoir-faire en termes de reconnaissance automatique de la parole multilingue. La transcription combinée à la traduction automatique multilingue par une voix artificielle est désormais possible. 7 questions à… Olivier Fraysse et Zoé Salaün LLPR - Pouvez-vous nous expliquer comment fonctionne la technologie de RAP, ou reconnaissance automatique de la parole, et comment évolue-t-elle ? OF et ZS - La reconnaissance automatique de la parole – souvent improprement appelée reconnaissance vocale – est une technique qui permet d’analyser la voix humaine captée au moyen d’un microphone. La technologie transcrit ensuite, sous la forme d’un texte ou d’un fichier exploitable sur ordinateur. Un système de reconnaissance automatique de la parole a pour but d’associer une séquence de mots à une séquence d’observation acoustique. Concrètement, un système de reconnaissance automatique de la parole comporte quatre modules : - Extraction de paramètres : permet de transformer le signal de parole en une séquence d’observation acoustique. Chaque phonème prononcé est différent. Un phonème prononcé par un locuteur différent ou par le même locuteur sera toujours différent (la coarticulation, les émotions, la vitesse d’élocution, les fréquences fondamentales de la voix plus ou moins aiguë, le timbre de la voix, etc.). On parle alors de variabilité intra ou extra-locuteur. De plus, le micro utilisé et l’environnement sonore (bruit, réverbération) font que le même phonème prononcé diffère en fonction de ces paramètres… Le but de l’extraction de paramètres est donc d’isoler les paramètres qui sont le plus invariants possible, lorsque le même phonème est prononcé. Il analyse également les paramètres les plus distants possible lorsque des phonèmes différents sont prononcés. Ceci, afin de les reconnaître de manière précise dans le modèle acoustique. - Modèle acoustique : permet de reconnaître une séquence de phonèmes grâce à une séquence d’observation acoustique (les paramètres précédemment extraits). - Modèle linguistique : permet de reconnaître les mots les plus probablement prononcés grâce aux mots voisins. On peut voir ce modèle comme un exercice de texte à trous où le but est de trouver un mot dans une phrase. - Dictionnaire phonétique : permet de relier le modèle acoustique et le modèle linguistique. Tous les mots possibles sont inscrits avec leurs différentes écritures phonétiques afin qu’une suite de phonèmes puisse permettre de trouver le mot probablement prononcé. Le décodage est la phase qui permet de maximiser la probabilité qu’une suite de mots (une phrase) soit prononcée grâce au signal sonore en entrée. On trouve donc la suite de mots la plus probablement prononcée d’après les modèles utilisés. LLPR - En quoi cette RAP peut-elle être un atout pour les contenus (textes, audio, vidéos…) des stations de radio et des podcasts ? OF et ZS - Cette technologie de reconnaissance automatique de la parole a de nombreux applicatifs et apportent des avantages de productivité indéniable, mais pas que ! Dans le monde de la radio et des podcasts, on travaille sur l’enregistrement, la captation audio et/ou vidéo, puis la diffusion de ce contenu pour qu’il soit le plus écouté, compris et partagé. La technologie de RAP va entrer en jeu à plusieurs niveaux pour apporter des solutions et des avantages concrets. D’abord, une fois l’enregistrement fait, il faut le retravailler, faire le montage et les ajustements. On va avoir besoin d’une transcription timecodée (le texte brut avec des repères temporels) pour analyser le contenu, trier ce que l’on garde ou pas et donc faire le montage final. De la même manière que pour une production audiovisuelle, cetteétape de dérushage est extrêmement longue et chronophage sans l’aide de la transcription automatique de la parole en texte. Le gain de temps ici est un véritable atout. Par la suite, nous voyons d’autres avantages qu’apporte la technologie de RAP au contenu final et mis en ligne : l’accessibilité numérique, l’indexation/référencement du contenu, l’augmentation de l’audience avec le multilingue (traduction). En effet, les solutions de transcription et sous-titrage en ligne basées sur cette technologie permettent d’obtenir le texte du contenu audio/vidéo en différents formats et rapidement. Avec des formats comme le HTML ou le XML de la transcription, le texte peut très facilement offrir un système de lecture synchronisé au mot près avec le player en ligne. De toute évidence, cela permet de rendre le contenu audio/vidéo accessible aux sourds et malentendants mais permet aussi à tout auditeur de naviguer très facilement et ludiquement dans l’enregistrement. Avec des formats sous-titres (.srt, .vtt), le contenu est tout de suite exploitable et diffusable sur les réseaux sociaux et les chaînes. Même sans le son (dans les transports, dans un open space, sans ses AirPods…), l’auditeur regarde le contenu, il est captivé. L’attention de l’audience sur un contenu audio/vidéo sous-titré est maximale. Que ce soit la transcription ou les sous-titres, ces deux résultats de la RAP permettent d’avoir le texte sur les contenus audio/vidéo. C’est grâce à ce texte que le contenu va être indexé ou référencé sur les moteurs de recherche. Le contenu audio ou vidéo va alors pouvoir remonter rapidement dans les résultats de recherche des auditeurs, il va y avoir ici un vrai gain en visibilité. Enfin, les stations de radio ou les podcasts qui souhaitent élargir leur audience à l’international en proposant leurs contenus traduits vont pouvoir le faire. Pour avoir le sous-titre traduit en anglais par exemple sur leur player, il faut d’abord avoir le sous-titre original ! Le multilingue est un atout additionnel que nous proposons chez Authôt. Tout ce travail autour du contenu audio-vidéo-texte permet de l’enrichir de façon optimale. |